第二次人工知能ブームでは、知識をたくさん与えることにより専門家のように振る舞うエキスパートシステムを開発しました。これは専門家の判断を支援するシステムとして一定の成功を収めましたが、より大規模なシステムを構築しようとすると、与える知識の関連性を事前に人手で定義しておくことなどが困難であるという課題に直面していました。
そのような中、1990年頃からのインターネットの普及に伴い、検索エンジンが急速に発展しました。この背景にあるのは統計的自然言語処理という機械学習の分野の技術です。統計的自然言語処理では、単語間の出現頻度の関連性を利用します。たとえば、たくさんの文章を利用して、ある単語の次にどの単語が出現し易いかを学習しておきます。すると、スペルミスや不正確な表現をはじくことができ、文章の校正に利用することができます。また、対訳コーパスという多言語間の翻訳文を記録したデータを用いて、ある単語が別の言語のどの単語に訳される確率が高いかを学習すれば、翻訳に利用することができます。
情報のデジタル化とそこから有意なデータを取り出す技術が相互に発達することにより、大量のデータを扱う環境が整備されていきました。
第三次人工知能ブームは、2000年代から現在まで続いており、機械学習の時代と考えられています。大量のデータを学習して判断基準を得る機械学習技術、さらにデータのどの部分に注目すべきかをも獲得する深層学習技術が発展しました。また、テキスト、画像、音声などの様々なコンテンツを生成可能な生成AIと呼ばれる技術が2023年頃に実用化され、その精度の高さと応用範囲の広さから驚きを持って迎えられています。
近年では、従来のルールに基づく処理をルールベースと呼び、ルールベースを含む機械による処理の自動化を広義のAIとみなす場合があります。この意味でのAI、ルールベース、機械学習、深層学習(ディープラーニング)の関係性を図1に示します。
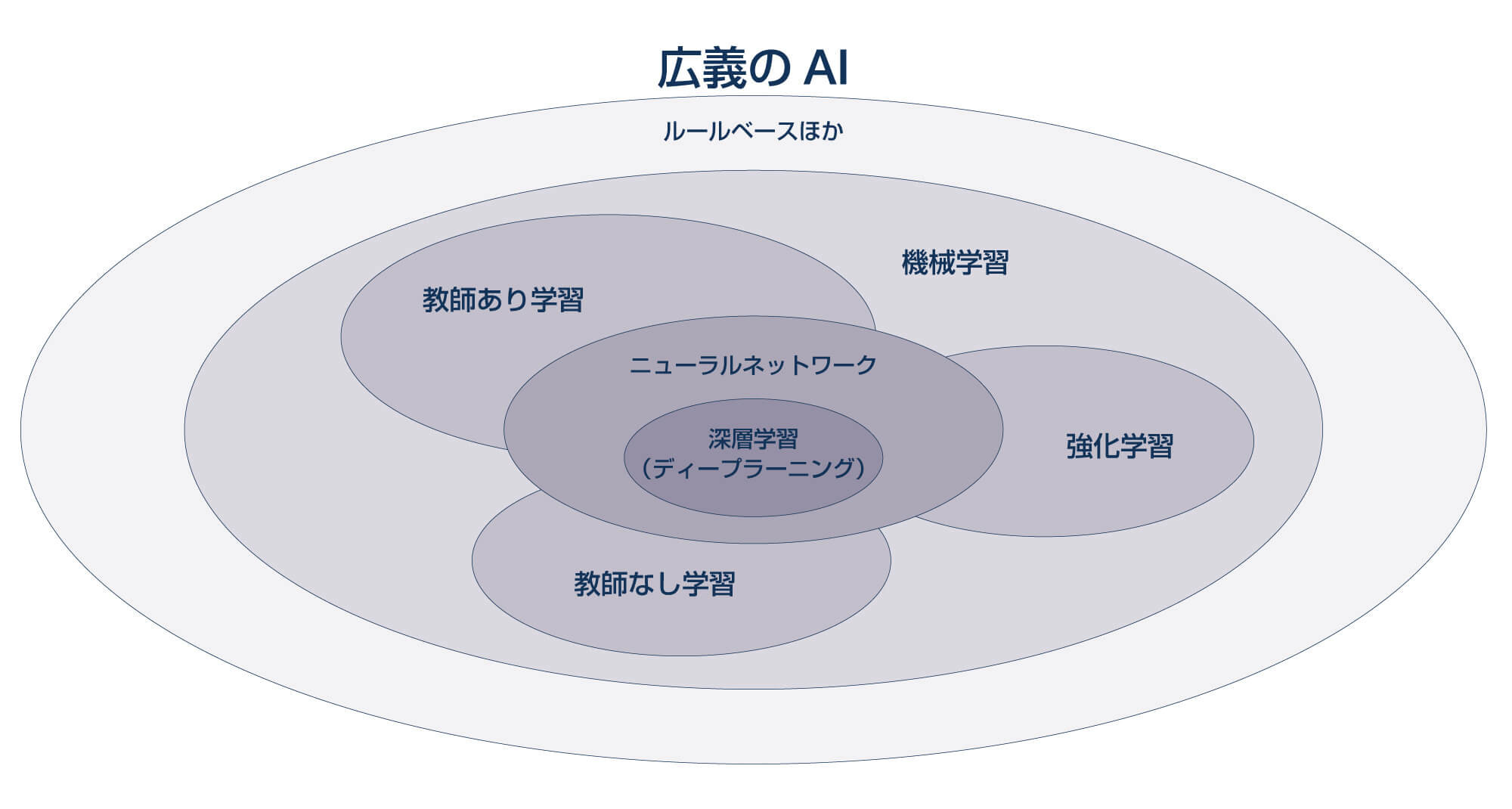
【図1】 広義のAIの概念図
学習するとは、分け方を学ぶことを意味します。ある製品に傷がついていないか、ある人にローンを通してよいか、あるユーザーにこの広告を出してよいか、...といった判断をしたり、これはボルトであれはナットだ、といった分類をすることは、イエス・ノー問題に帰着します。機械学習は、大量のデータを与えて処理させることにより、データの分け方をコンピュータ自身に獲得させる技術です。学習によりボルトの見分け方を一度習得すれば、次にボルトの画像を見たときに、これはボルトだと判断できるようになります。
機械学習では、どのようなデータを学習に用いるかが重要になります。たとえば年収を予測する問題の場合、職種や勤務地は関連性が高そうですが、身長や体重はあまり関係が無さそうに思われます。また、生年月日というデータは、そのまま利用するよりも、現在との差である年齢というデータに加工した方が有用なデータとなります。このように、注目対象からどのようなデータを抽出し続く処理に渡すかは重要であり、対象から抽出したデータは特に特徴量と呼ばれています。
機械学習では、データを入力し学習させれば、機械が自ら判断基準を獲得できる点が強力な技術でした。しかしながら、どのようなデータを入力として与えるのが適切か、言い換えればどのような特徴量を与えれば良いのか、という特徴量設計と呼ばれる前処理部分は、そのデータの特徴を十分に理解した人が設計する必要がありました。このように、従来の機械学習の手法は人の手助けが必要であり、完全な自動化はできない技術でした。
近年注目されている深層学習と呼ばれる技術は、与えられた大量のデータを処理する中で、判断基準に加えてデータのどの部分に注目すべきかという特徴量も機械が自ら獲得します。これにより、人の手を介さず機械のみで完全に自動化された学習ができるようになりました。この点がこれまでの手法と一線を画しており、革新的な技術と位置付けられている理由です。
しかしながら、深層学習にも課題はあります。産業利用という観点で、機械学習と深層学習のメリット・デメリットを整理すると、表1のようになります。
| 機械学習 | 深層学習 | |
|---|---|---|
| ① 判断結果の解釈可能性 | 〇 | △ |
| ② 学習に必要なデータ数 | 〇 | △ |
| ③ 計算コスト | 〇 | △ |
| ④ 複雑なパラメータの学習 | △~〇 | 〇~◎ |
機械学習の手法では、入力データの一部や全体の値あるいはそれらの統計量から特徴量を計算するように設計されています。計算過程が明確であるため、ユーザーはどのパラメータのしきい値をどのように調整すべきかなどを直感的に理解しやすくなっています。学習に必要なデータ数は、画像であれば数枚~百枚程度となります。計算環境としては、生産現場での使用を想定した製品であれば、特別な環境を必要とせずに従来の産業用PCの性能で実現可能なものもあります。
深層学習の手法は、層状に重ねられたニューラルネットワークを指しており、内部パラメータである重みの最適な組み合わせを獲得するように学習が進みます。学習が完了すると、入力データを適切に判断できるような重みを獲得します。他方、学習完了後に新たなデータを入力してその判断が誤っていた場合、学習した重みの調整によって判断を修正することは困難です。標準的な多層のニューラルネットワークでは、学習後の重みを解釈しようとしても、どの重みがどのように判断結果に寄与しているのか単純には理解できません。そのため、深層学習は解釈可能性が低く、ブラックボックスであると言われることがあります。学習に必要なデータ数は、数百枚~数千枚となります。計算環境にはGPUを積んだPCやクラウド環境が必要となります。このようにコストはかかりますが、特徴量設計が不要で自ら判断基準を獲得できるという利点を活かすと、データに精通したベテラン人員が限られている場合や、従来の処理ではパラメータが複雑になりすぎる場合の代替手段としての利用が考えられます。
これまでの技術発展の年表を図2に示しました。第一次人工知能ブームから第三次人工知能ブームまでを中心に、各年代で発展した手法と、実用化された技術を記しています。
深層学習の技術は2012年の画像認識コンペティションでのトロント大学のチームの優勝で大きく注目されて以降、2024年現在まで継続して発展しています。2022年末にはOpenAI社からChatGPTが公開され大きな反響を呼びました。
従来のルールベースの処理や機械学習技術も産業では現在も幅広く使われています。たとえば画像処理システムによる外観検査では、2値化やラベリングといった基本的な画像処理技術は最も多用されています。これらは完成された技術であるため高速に動作し、輝度値を判定基準としたり、特徴量として面積を用いることも直感的で説明性が高いため、小回りの利く生産性の高いシステムを構築できるからです。
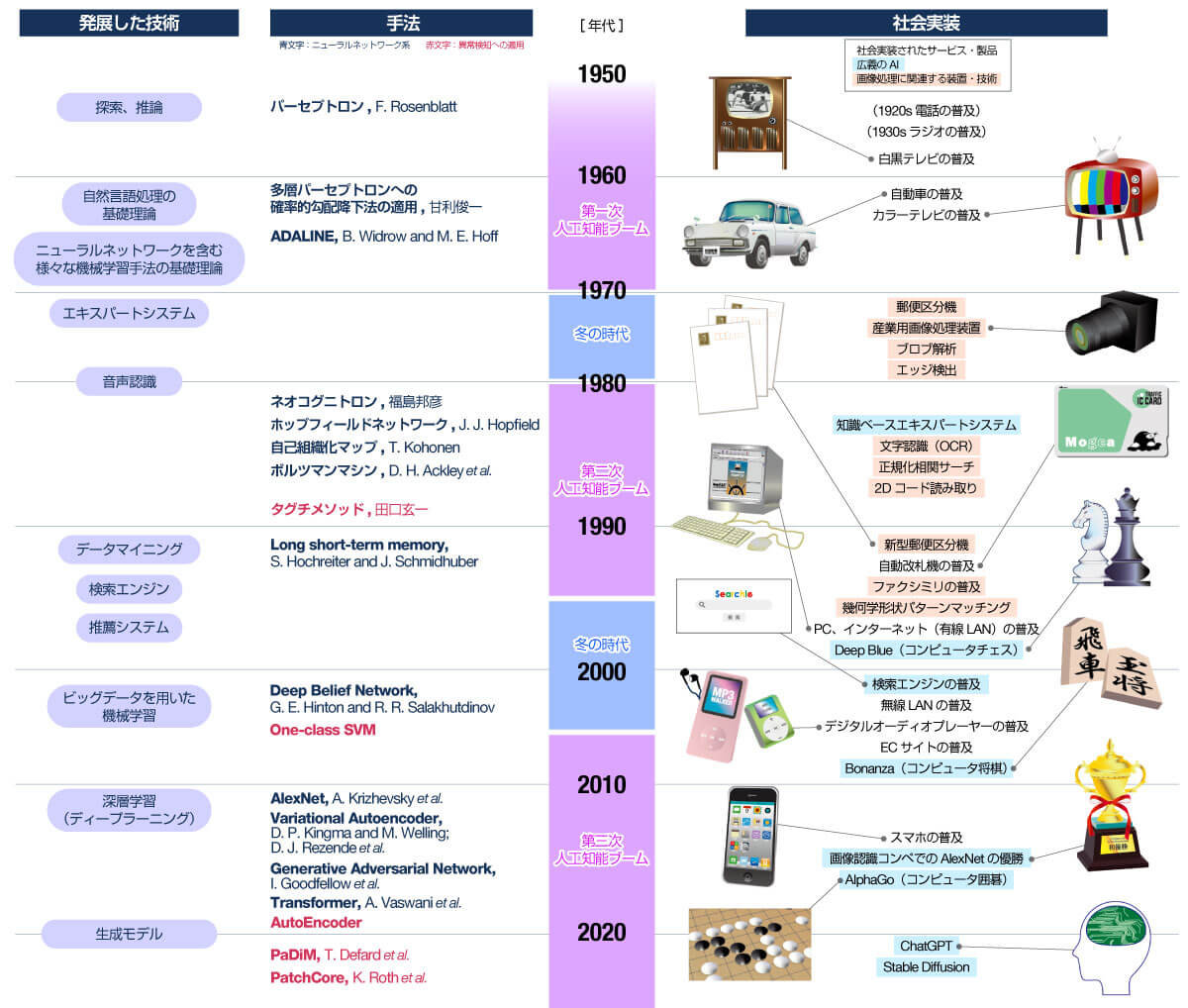
【図2】 技術発展の年表
画像処理技術の紹介ページは本ページ下部で案内しています。
[1] 総務省 平成28年版 情報通信白書
[2] 総務省 令和元年版 情報通信白書
[3] 総務省 令和6年版 情報通信白書
[4] 松尾豊 「人工知能は人間を超えるか ディープラーニングの先にあるもの」 KADOKAWA/中経出版 2015
>画像処理装置
>ブロブ解析
>エッジ検出
>正規化相関サーチ
>2Dコード読み取り
>幾何学形状パターンマッチング

成長分野ならではのダイナミックな展開を、正確かつ柔軟に、
読みやすい内容とコンパクトなサイズでお届けします。


私たちは、外観検査・画像処理検査に関するエキスパート集団です。単なるメーカーではなく、画像処理アルゴリズム、光学技術、電気・機械の知識と経験を兼ね備える外観検査・画像処理検査装置メーカーとして、総合的なコンサルティングも可能とする、開発型エンジニアリング企業です。
